


Don’t stare into the abyss for too long. Not only might it stare back at you, but you might miss other interesting abysses to stare into. And sometimes it is instructive to compare abysses. In what follows, I will touch on three examples in which one data set is put on top of another (literally, via a diagram), providing new insight.
Example 1: data from different countries
Just the other day,
from USMortality discussed data on deaths by Covid vaccination status from the Netherlands. I downloaded the data myself, and plotted proportions of vaccinated among deaths for the different categories (the horizontal axis shows calendar weeks of 2021 and 2022):
The data distinguish between Covid-19 deaths (C19) and other deaths (no C19), and between deaths of people in long-term care (LTC) and outside long-term care (no LTC). Furthermore, two definitions of being “vaccinated” are on offer: immediately after first vaccination (solid lines), and after some purgatory (dashed lines). Since the latter definition commits the usual cheap trick Bayesian datacrime, I included it in the image only to reassure myself that the dashed lines are always below the solid lines. Now we can forget about them and concentrate on the solid lines. Since LTC should correlate with age and vaccination uptake, red should lie above blue, and green above yellow. Covid-19 deaths are much rarer than other deaths, so the C19 graphs (read and blue) are rather more jagged than the no-C19 graphs (green and yellow). If the vaccines are of any use, green should lie above red, and yellow above blue. They do, sort of, but it’s a close call in 2022, and might just reflect healthy user bias or something.
Anyway, I promised to throw in another data set. I went back to my German ICU data (ICU Covid patients from the DIVI register; “with” Covid, not necessarily “because of” Covid), and extracted the vaccination rates. Here they are, in purple, and with the previous lines slightly thinned:

The country is different, the criterion is different (deaths vs ICU), age structure and vaccine uptake are surely different, and yet the data fit together nicely (the best fit should be expected to the red C19, LTC category). Unfortunately, the data from the Netherlands do not extend into 2023. Somebody should push a FOIA request on that, and also squeeze out data by age.
Example 2: data from different sources
On new year’s eve of 2023, I compared different ways to compute Covid case rates for Germany. The Robert-Koch Institut (RKI) is now following suit: the latest GrippeWeb reports contain similar pictures. Here’s the one from calendar week 8 of 2024:

And here’s the overlay of my image with the RKI image (yellow background):

Isn’t it hilarious that the public now blithely ignores case rates of 3,000 per 100,000, and we had “emergency break” laws requiring the shitting of pants when hitting 200 per 100,000?
Example 3: data from the present versus models from the past
In late summer of 2021, the German STIKO recommended Covid vaccination of children aged 12-17 based on a (SEIR) model. Here’s figure 4 from their report, showing the history of recorded Covid cases (until August 2021) and a model of a fourth wave:
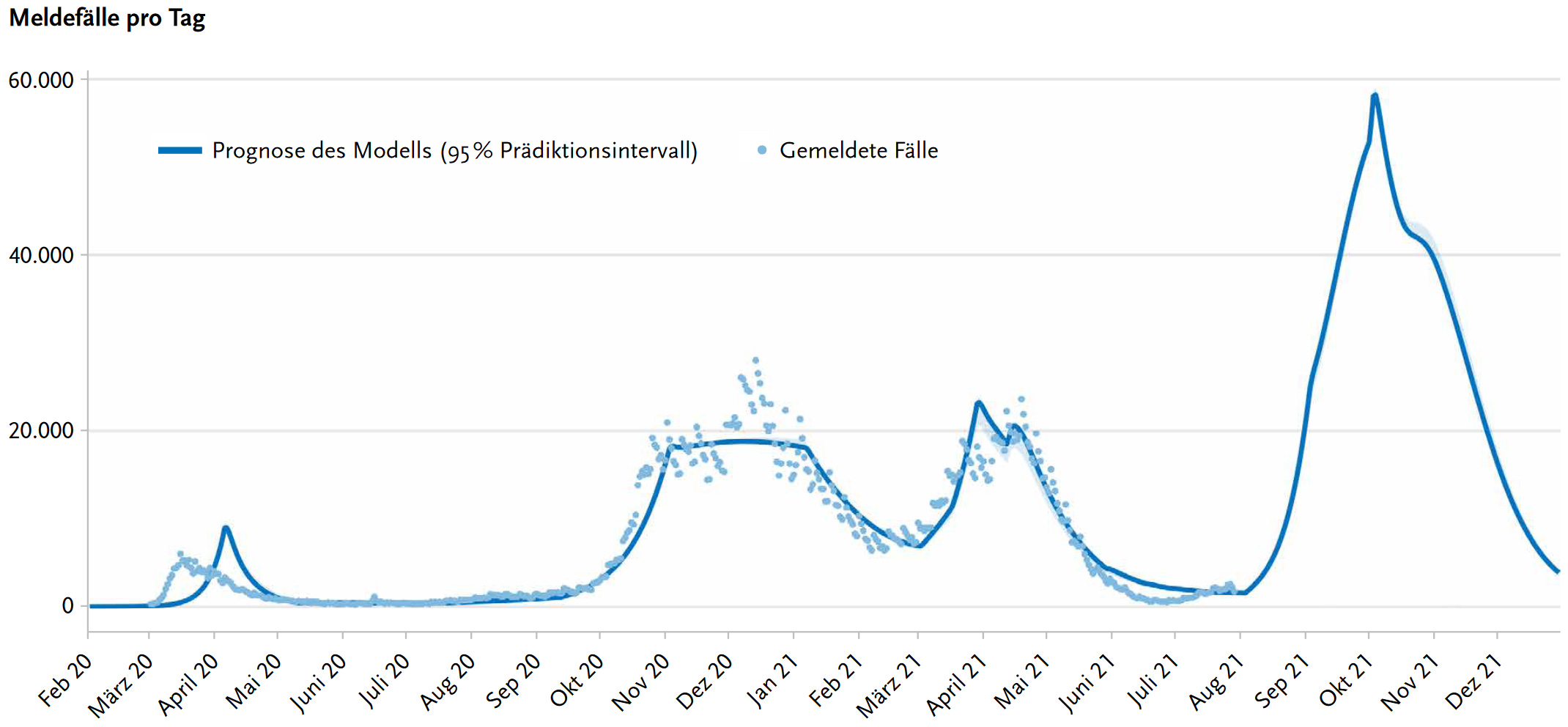
And here’s what actually happened, again using my diagram:

In fact, their modelling of the fourth wave wasn’t that bad. It happened a little later, but case rates were as modelled. But then came Omicron, and although the actual vaccination rate among children aged 12-17 was much higher than anticipated (70% versus 50%), the promised reduction in infections never came.
What came, however, were cases of vaccine-induced myocarditis. The STIKO model predicted only 82 (Table 15), but even the Paul-Ehrlich Institut (PEI), a mighty downplayer of vaccine damage before the Lord, now admits 279 possible cases. Apply your preferred underreporting factor, and weep.